Shannon entropy
Continuous case: differential entropy.
Given a discrete probability distribution
It quantifies the uncertainty or randomness in the distribution. A higher entropy indicates a more uniform (less predictable) distribution. In a sense, is the "surpriseness" of a probability distribution.
In the discrete case,
According to Maldacena in this video it is a measure of the missing information in a message. For example, the sentence "Maria was preparing..." can have different continuations. But "Maria was preparing the dinner" is closed. The first one has entropy.
Formally, this “missing information” corresponds to the probability distribution over possible continuations of the message: when many continuations are plausible with comparable weights, the entropy is high; when the continuation is essentially fixed, the entropy is low (ideally zero). Thus Maldacena’s description is an intuitive restatement of Shannon’s definition, where entropy quantifies the uncertainty in which outcome (or continuation) will occur.
Entropy and guessing games
In a guessing game ("Wordle" or "Guess who", for example), we have a space of answers
In each stage of the game we say we gain some information, meaning that we reduce the space of possible answers to a smaller subset of
For example, if we obtain information to reduce the uncertainty area to one half, we say we have obtained 1 bit
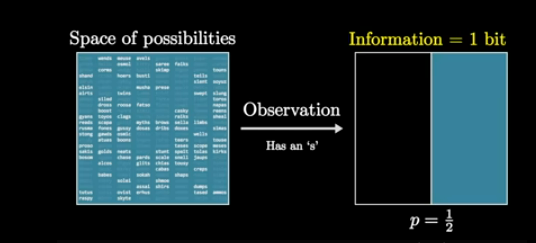
For that purpose we make a guess, a question, which induces a partition in the space
where
The central challenge in games like "Wordle" or "Guess Who?" is to acquire a specific amount of information while being constrained by the types of questions you're allowed to ask. At the heart of any guessing game is one ultimate, "master question" that would solve it instantly. For "Guess Who?", this question is "Which of the N characters is it?"
This question creates the most granular partition possible, where each of the
This value represents the total information required to win the game. For a 24-character board, this is
The crucial rule of the game is that this master question is forbidden. The entire game is about substituting this single, powerful question with a series of smaller, less informative (but legal) questions.
For a mathematical proof that the minimum average number of binary questions required to determine an outcome of a random variable
Related: